

优化Linux内存性能的核心思想-提升系统效率秘诀
事实上,CPU的L1,L2,L3 cache:不就是这个方案设计的吗?这事实上已经成为cache设计的不二法门。这个设计思想:同样作用于slab,就是Linux内核的slub实现,现在可以给出概念和解释了。
Linux kernel slab cache::一个分为3层的对象cache模型。 Level 1 slab cache::一个空闲对象链表,每个CPU一个的独享cache,分配释放对象无需加锁。 Level 2 slab cache::一个空闲对象链表,每个CPU一个的共享page(s) cache,分配释放对象时仅需要锁住该page(s),与Level 1 slab cache互斥,不互相包容。 Level 3 slab cache::一个page(s)链表,每个NUMA NODE的所有CPU共享的cache,单位为page(s),获取后被提升到对应CPU的Level 1 slab cache,同时该page(s)作为Level 2的共享page(s)存在。 **共享page(s)**:该page(s)被一个或者多个CPU占有,每一个CPU在该page(s)上都可以拥有互相不充图的空闲对象链表,该page(s)拥有一个唯一的Level 2 slab cache空闲链表,该链表与上述一个或多个Level 1 slab cache空闲链表亦不冲突,多个CPU获取该Level 2 slab cache时必须争抢,获取后可以将该链表提升成自己的Level 1 slab cache。该 slab cache: 的图示如下:
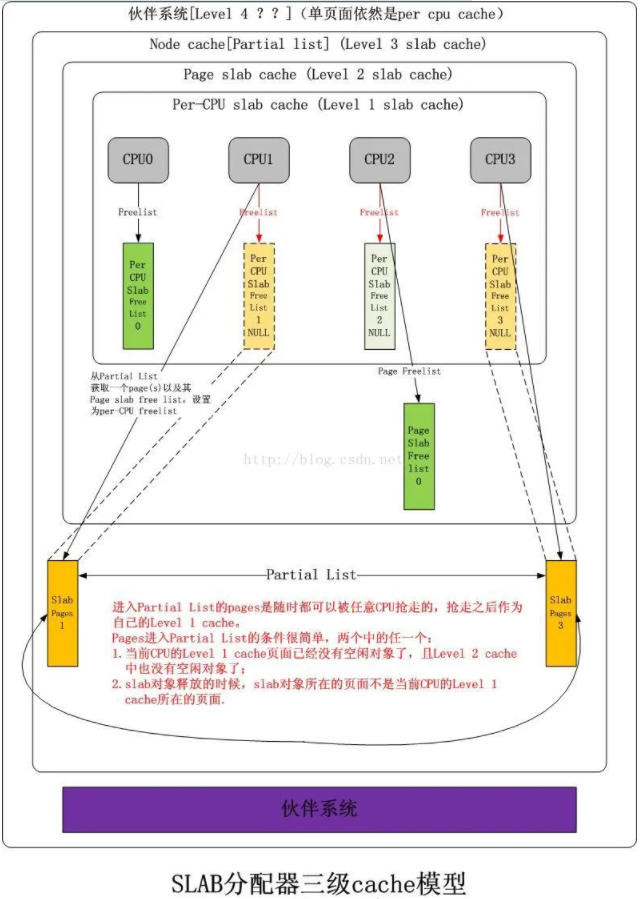
其行为如下图所示:

2个场景
对于常规的对象分配过程,下图展示了其细节:

事实上,对于多个CPU共享一个page(s)的情况,还可以有另一种玩法,如下图所示:

伙伴系统
前面我们简短的体会了Linux内核的slab设计,不宜过长,太长了不易理解.但是最后,如果Level 3也没有获取page(s),那么最终会落到终极的伙伴系统,伙伴系统是为了防内存分配碎片化的,所以它尽可能地做两件事:
尽量分配尽可能大的内存: 尽量合并连续的小块内存成一块大内存:我们可以通过下面的图解来理解上面的原则:

注意,本文是关于优化的,不是伙伴系统的科普,所以我假设大家已经理解了伙伴系统。
鉴于slab缓存对象大多数都是不超过1个页面的小结构(不仅仅slab系统,超过1个页面的内存需求相比1个页面的内存需求,很少),因此会有大量的针对1个页面的内存分配需求。从伙伴系统的分配原理可知,如果持续大量分配单一页面,会有大量的order大于0的页面分裂成单一页面,在单核心CPU上,这不是问题,但是在多核心CPU上,由于每一个CPU都会进行此类分配,而伙伴系统的分裂,合并操作会涉及大量的链表操作,这个锁开销是巨大的,因此需要优化!
Linux内核对伙伴系统针对单一页面的分配需求采取的批量分配“每CPU单一页面缓存”的方式!每一个CPU拥有一个单一页面缓存池,需要单一页面的时候,可以无需加锁从当前CPU对应的页面池中获取页面。而当池中页面不足时,系统会批量从伙伴系统中拉取一堆页面到池中,反过来,在单一页面释放的时候,会择优将其释放到每CPU的单一页面缓存中。
为了维持“每CPU单一页面缓存”中页面的数量不会太多或太少(太多会影响伙伴系统,太少会影响CPU的需求),系统保持了两个值,当缓存页面数量低于low值的时候,便从伙伴系统中批量获取页面到池中,而当缓存页面数量大于high的时候,便会释放一些页面到伙伴系统中。
小结:
多CPU操作系统内核中,关键的开销就是锁的开销。
我认为这是一开始的设计导致的,因为一开始,多核CPU并没有出现,单核CPU上的共享保护几乎都是可以用“禁中断”,“禁抢占”来简单实现的,到了多核时代,操作系统同样简单平移到了新的平台,因此同步操作是在单核的基础上后来添加的。
简单来讲,目前的主流操作系统都是在单核年代创造出来的,因此它们都是顺应单核环境的,对于多核环境,可能它们一开始的设计就有问题。
不管怎么说,优化操作的不二法门就是禁止或者尽量减少锁的操作。随之而来的思路就是为共享的关键数据结构创建”每CPU的缓存:“,而这类缓存分为两种类型:
1. 数据通路缓存:
比如路由表之类的数据结构,你可以用RCU锁来保护,当然如果为每一个CPU都创建一个本地路由表缓存,也是不错的,现在的问题是何时更新它们,因为所有的缓存都是平级的,因此一种批量同步的机制是必须的。
2. 管理机制缓存:
比如slab对象缓存这类,其生命周期完全取决于使用者,因此不存在同步问题,然而却存在管理问题。
采用分级cache的思想是好的,这个非常类似于CPU的L1/L2/L3缓存,采用这种平滑的开销逐渐增大,容量逐渐增大的机制,并配合以设计良好的换入/换出等算法,效果是非常明显的。